事情起因是这样的,一天学长找到我说:”学弟啊,你有没有空啊。现在跑机器学习实验,跑3个月结果还跑不出来,你能不能帮我优化一下代码啊?”
我心想:“一次实验跑三个月,万一写了一点bug,实验不又得重头再来三个月,这也太令人头皮发麻了吧?“
于是我开始了实验代码优化之旅。
1.整体思路
该项目整体代码量非常多,实验室内已经维护了3~4年,整个项目构建在Pytorch上,会到大数据集进行聚类学习。一次实验涉及到的数据量很大,基本是TB级别。
仔细看了实验项目框架和执行过程,一时间没有优化思路。
问了学长,目前所有实验执行都是单核CPU,没有多线程多进程。
那优化思路不就有了——并行化,如果可以开多个进程同时跑实验,效率直接可以翻几十倍(当然最终受限于硬件资源)。
要代码并行化,要满足以下几个条件
有大量的、重复的、类似的任务,CPU密集型任务
目前实验时间开销都主要用在聚类操作中,一次实验大概要做800w次聚类,平均一次聚类1s。单核跑大概需要3个月。
并行任务之间不能有依赖关系
现有聚类之间有弱依赖关系,但是通过代码逻辑修改可以去掉依赖关系。
因此想到可以把聚类运算给单独拿出来,用多线程聚类来提升效率。
多线程并行化跑大量任务,很容易就想到MapReduce计算框架。
将计算过程分为Map,Reduce两个过程。将大任务分为多个子任务,提前准备好每个子任务的输入数据。Map过程多个Worker(线程、进程)执行执行,完成子任务。Reduce过程将所有子任务结果聚合,形成最终大任务结果。
那么整体的实现思路就有啦:
- 数据准备:输出聚类输入数据
- 任务拆分:将聚类输入分为多个子任务
- 多机执行:多进程、多机器并行执行聚类
- 结果合并:汇聚聚类结果得到最终结果
2.数据准备
要跑并行化代码,首先要把任务所需要的输入数据准备好,即导出聚类输入数据。
代码执行过程分析
聚类数据导出是比较典型的IO密集型任务,可是测试了一下,发现把聚类数据导出就要几天时间。
理论上磁盘IO速度没有这么慢,因此怀疑数据输出过程中有复杂的CPU运算。
尝试用pyinstrument工具分析了代码的执行过程和每个过程的执行时间。
Pyinstrument 是一个Python 分析器。 以可视化的形式帮助您优化代码,使其更快。 输出信息包含了记录时间、线程数、总耗时、单行代码耗时、CPU执行时间等信息。
这一分析就发现一个大问题,可视化结果如下图。
输出聚类函数也就是_out_clustering_values执行了311s,其中有137s的时间浪费在一个unique函数上。
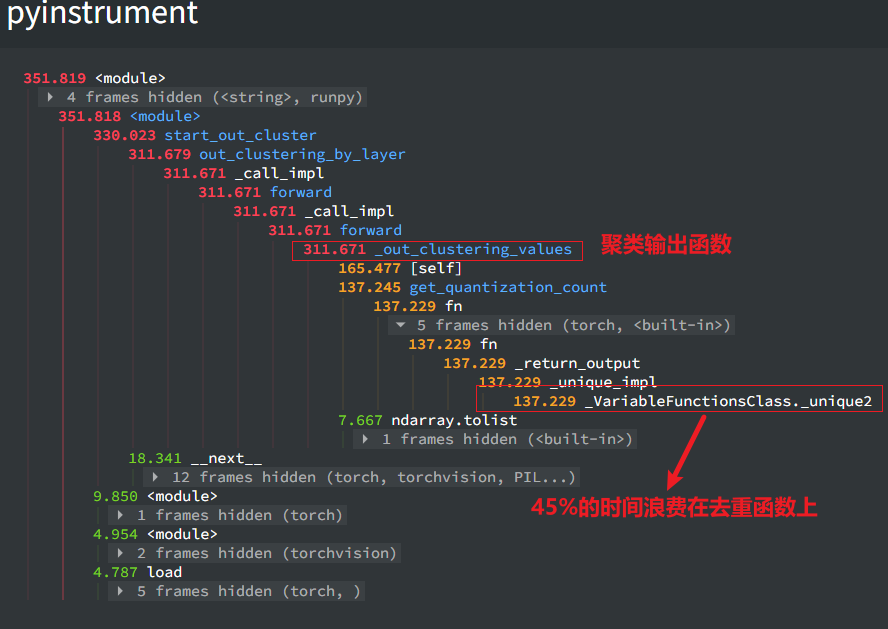
仔细分析了对应的代码,unique函数每次都要对几百万的数据做去重,仅仅只为了计算聚类数。然而这根本没有必要,因为一般聚类数远小于聚类输入数据(比如100w数据 聚成128类),这样可以把聚类数设为一个定值。果断将unique函数去掉,整体效率提升45%。
除开unique函数,代码执行过程中还发现一些其他没有必要的小函数,也一并做了优化或去除。
IO密集型优化
对于数据导出,没有复杂的CPU运算,是比较典型的IO密集型任务。
对于IO密接型任务的优化主要从两方面进行优化
提升单次磁盘写入数量:
- 仔细看了学长的代码,写入文件用的是默认的buffer,只有8192byte。而导出的数据量级为TB,buffer太小导致IO次数过多。
- 通过加上一个大IO缓冲buffer(比如64MB),大幅减少IO次数。
减少总体数据大小:
- 实验用到的聚类数据都是Float型,学长将Float转为字符形式然后写入文件。但是更优化的方法是转为二进制形式,相比于字符形式表示的Float,二进制空间减少接近4倍。
- 根据计算,输出的数据总共有10TB,而服务器的磁盘可用容量只有7T,优化后输出数据为2.1TB。
- 这期间还尝试过把数据先压缩后再写入磁盘,但发现压缩本身相较于磁盘IO更耗费时间,遂放弃。

3. 任务拆分
一次实验聚类数据有2T左右,不可能一次性load进内存进行运算,因此需要对聚类数据做拆分,形成一个个小任务。小任务并发执行,然后将小任务的执行结果进行合并。
任务拆分本身逻辑比较简单,但是有几个注意点:
聚类数据间有前后顺序,因此要对拆分的任务做好编号,之后需要按顺序合并回去。
任务拆分大小要适中
- 任务过大会导致一次任务执行过长,单次失败成本高、此外内存开销大。
- 任务过小导致每次任务执行太快,CPU忙于切换进程而影响性能,此外任务数量太多不方便查看
最终的实现是分两层对数据做拆分,第一层根据机器学习模型的各层划分,第二层按照聚类数据,每64~256MB切分为一个子任务。
分层的任务划分可以给任务带上业务属性,方便后续重复实验。因为实验优化往往是针对某几层做优化,这样只需要重新跑这几层的任务即可。
4. 多机执行
任务拆分好后,就可以使用多进程同时执行任务,充分压榨硬件性能。这里面也有两步优化,第一步是单机多进程,第二步是多机多进程
单机多进程
python由于GIL(全局解释器锁)的存在,没法真正意义上的并发执行多线程。
所以需要使用python多进程,这里选择了python官方库multiprocessing中的进程池管理多进程。
除开实现多进程聚类的功能需求外,还自己实现了一些非功能性需求:
日志输出:
- 对于多进程,同时读写一个日志文件会导致竞争问题。这里选择了
concurrent_log_handler对日志文件进行加锁,避免并行冲突。
- 对于多进程,同时读写一个日志文件会导致竞争问题。这里选择了
支持随时启停:
- 任务执行过程中可能由于各自原因失败了,要支持任务从失败的地方继续跑。
- 解决思路是建立tmp目录,执行过程中的数据保存在tmp目录下,任务完成后将执行结果拷贝到result文件夹下。
- 此外单个任务切分不要太大,这样可以降低执行失败时的成本。
失败任务重试:
- 任务执行过程中可能由于各自原因失败了,将自动重试几次。失败任务将单独打印日志,便于分析失败原因。
结果完整性检查:
- 多进程任务执行完后,需要对结果文件总数量进行校验。如果结果文件少于预期,将自动重新执行未完成的任务。
其他一些统计功能:
- 支持查看进度、总任务数。
- 支持测算时间、预计时间。
看了下实验室服务器有16个核,32个线程,效率应该可以翻32倍,理论上3个月的任务,3天应该可以跑完。
下面是任务执行输出的日志部分截图:
多机多进程
实验室有多台机器,如果多机一起跑聚类,可以进一步提升效率。
多台机器同时执行任务,首先要解决的问题是聚类数据同步到多个机器上。这里有几个选择:
直接通过移动硬盘拷贝,把输入数据copy到其他机器上
不可行:当时正值10-1国庆期间,实验室管机房的老师都下班了,机房进不去。
在其他机器上重新导出一份聚类输入数据
理论可行,但不是最优的:几台机器配置各不相同,有些机器硬盘容量只有500G,而整个待聚类数据有2.1T。如果只导出部分聚类数据,需要针对不同机器改代码,颇为繁琐且容易出错。
其他机器到主机器上下载子任务,下载多少就执行多少
这是最终选择的方案,其他机器通过ssh下载主服务器上的任务数据,每下载一个子任务,就启动一个进程执行。这样屏蔽了各个机器的配置差异,且支持添加新机器,老机器下线。
于是写了一份工具类File_Transfer,使用ssh 从远端拉取数据的代码。
现在相当于获取任务数据有两种方式,一种是从本地直接读取,一种是从远端通过网络拉取。
这期间还尝试过很多种下载数据的方法,比如rsync 、scp等命令。
但这些命令方法没法和多进程脚本结合起来,且不好管理数据量,因此最后还是自己写了一份python代码,做更精细化的管理。
多机跑出实验结果后,先各自进行结果文件的合并,然后多机再把结果文件传到主服务器上进行第二次合并。因为结果文件比较小,只有100MB不到,因此也不需要额外的优化。
终于并行化实验顺顺利利的跑起来了,整个聚类过程从原来的3个月跑不出来,到现在3天跑出结果。性能优化明显。
不过这只是整个实验的一小步,距离做完整个实验,似乎还有一大段路要走。
其他
在这次优化过程中,还学到了许多linux指令,用到了许多曾经学到过的知识
统计当前目录下文件的个数(包括子目录),用来统计任务总数和执行情况
1
ls -lR| grep "^-" | wc -l
统计文件大小
1
du -sh
linux查看网络使用情况
1
iftop -n
linux查看磁盘IO情况
1
iotop
python 内存占用分析 Memray
python 耗时分析 pyinstrument