Redis学习
Redis数据结构
- string–>简单的
key-value - list–>有序列表(底层是双向链表)–>可做简单队列
- set–>无序列表(去重)–>提供一系列的交集、并集、差集的命令
- hash–>哈希表–>存储结构化数据
- sortset–>有序集合映射(member-score)–>排行榜
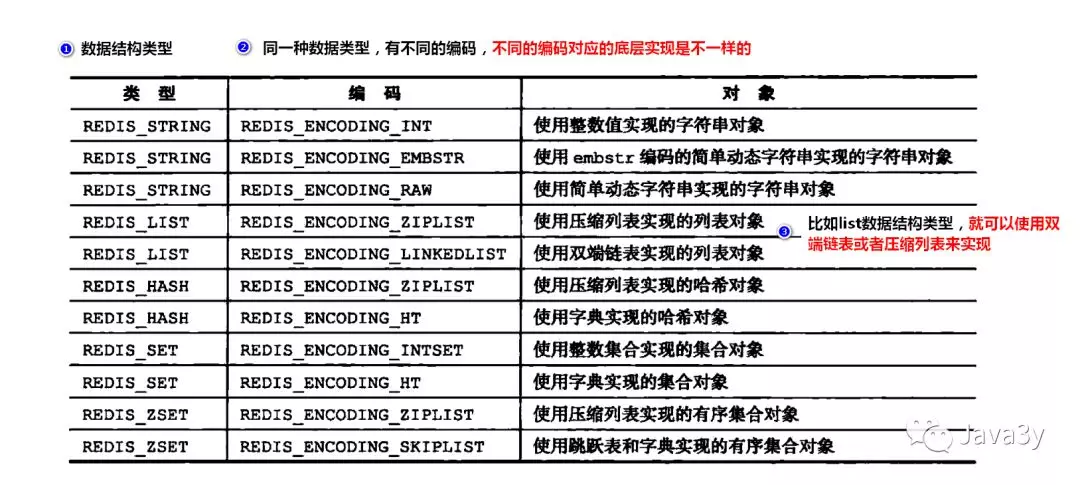
string
- encode_int
- encode_embstr
- encode_ram
List
- ziplist
- linkedlist
hash
- ziplist
- hash table
set
- intset 整数有序集合(一个数组)
- hash table
sortset
- ziplist
- skiplist 跳表
为什么Redis选择使用跳表而不是红黑树来实现有序集合?
Redis 中的有序集合(zset) 支持的操作:
- 插入一个元素
- 删除一个元素
- 查找一个元素
- 有序输出所有元素
- 按照范围区间查找元素(比如查找值在 [100, 356] 之间的数据)
其中,前四个操作红黑树也可以完成,且时间复杂度跟跳表是一样的。但是,按照区间来查找数据这个操作,红黑树的效率没有跳表高。按照区间查找数据时,跳表可以做到 O(logn) 的时间复杂度定位区间的起点,然后在原始链表中顺序往后遍历就可以了,非常高效。
Redis 持久化
两种
RDB(快照持久化)
RDB持久化所生成的RDB文件是一个经过压缩的二进制文件,Redis可以通过这个文件还原数据库的数据。
AOF文件
AOF是通过保存Redis服务器所执行的写命令来记录数据库的数据的。
-AOF 重写
主从复制模式
三个阶段
连接建立阶段
保持主节点信息,建立socket连接,身份验证等等
数据同步阶段
完全同步:常见于服务器第一次同步,主服务器生成RDB文件,将RDB文件发给从服务器,从服务器由RDB文件建立缓存
部分同步:常见于短线重连,断线重连时只同步缺失的数据。主从服务器分别记录数据偏移量offset,主服务器不仅将命令发给从服务器,还将写命令写入复制积压缓冲区。在短线重连时,只要缺失的写命令还能从复制积压缓冲区中,就只需要部分同步。否则完全同步。
另外,从服务器会记录上次复制的主服务器的 Run ID,断线重连时如果run id 不一致,说明之前复制的主服务器和现在服务器时两台服务器,则进行完全同步
命令传播阶段
每次主服务器执行写命令后,将命令发给各个从服务器,从服务器执行相同的命令。
另外还会默认以1s一次向主服务器发送心跳检测
- 检测主从网络状态
- 检测是否由命令丢失,从服务器发送的包带有offset
主从复制的一些问题
数据存在延迟和不一致
数据过期的问题
数据已经过期,但是从服务器上还存在
可用性问题
主节点死掉,则无法执行写命令——通过哨兵机制解决。
写单点问题,存储能力受单机限制—— 通过集群模式解决
哨兵模式
启动多个哨兵,哨兵是一种特殊的redis节点,本身不存储数据,只监视其他节点。
定时任务:每个哨兵执行3个定时任务来监视其他节点
- 向主从节点发送info 命令获取最新的主从结构
- 接收其他哨兵节点的信息(推选,客观下线时有用)
- 向其他节点发送ping命令进行心跳检测,判断是否下线
主观下线:心跳检测时节点超过一定时间没有回复,则认为主观下线
客观下线:如果时主节点被主观下线后,哨兵节点会询问其他哨兵节点,如果超过一半的哨兵节点都认为其下线(所以哨兵节点数量应为奇数),则认为主节点下线,开始故障转移。
选举领导哨兵节点:先到先得选取领导者
故障转移:领导哨兵节点 选取最合适的从节点成为新的主节点。根据优先级/延迟/复制偏移量等选取。
集群模式
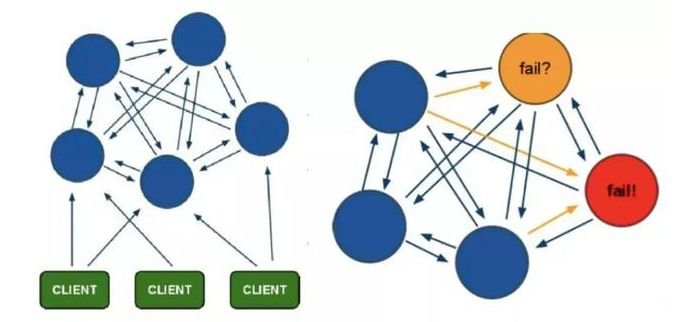
集群模式首先时将数据分片,将整体数据分布到多个redis节点上,从而扩展容量实现集群。数据分片算法采用哈希槽的分片算法。
(1)Redis对数据的特征值(一般是key)计算哈希值,使用的算法是CRC16。
(2)根据哈希值,计算数据属于哪个槽。
(3)根据槽与节点的映射关系,计算数据属于哪个节点。
将数据分开存储在不同主节点上后,就实现了数据的扩容和单写节点的问题。每个主节点还可以再搭配多个从节点,实现主从复制,实现读写分离。另外每个主节点充当集群中的哨兵,保障高可用性。
集群模式就是再哨兵机制上加一层数据分片。在Redis3.0前,官方并不支持集群模式,可以通过一个中间件代理(Proxy),该中间件存储数据分片的位置,每个数据分片就是一个哨兵模式(主从+哨兵)。也可以实现集群模式。
集群模式的缺点:
实现复杂,资源开销大,不适合数据量小的情况。
默认从节点不分担读请求,只作为数据备份保障高可靠性,资源开销大
Key批量操作受限制,数据分布再多个节点上,对Key进行批量操作时只能对同一节点的key操作,不同节点受限制。
Key 作为数据分区的最小粒度,不能将一个很大的键值对象如 hash、list 等映射到不同的节点。
Redis 分布式锁
https://xiaomi-info.github.io/2019/12/17/redis-distributed-lock/
Redis 锁主要利用 Redis 的 setnx 命令。(set if not exit)
加锁命令:SETNX key value
锁超时:EXPIRE key timeout(必须要有的,保证即使锁未被显示释放,也能超时释放,避免死锁)
解锁命令:DEL key
- SETNX 和 EXPIRE 非原子性——通过lua脚本解决(原子性操作)
- 业务执行时间大于锁超时—— 锁误消除,并发执行
锁的value记录占有锁的线程ID,释放锁时判断线程ID是否为本线程
将过期时间设置足够长,确保代码逻辑在锁释放之前能够执行完成。
为获取锁的线程增加守护线程,为将要过期但未释放的锁增加有效时间。
不可重入
- 本地记录锁重入次数
- Redis Map 记录
- 无法等待锁释放:被锁阻挡的线程希望在锁释放后继续执行操作
- 轮询
- 使用Redis 发布订阅功能,订阅锁释放消息
常见问题
缓存雪崩
缓存雪崩的情况是说,当某一时刻发生大规模的缓存失效的情况,比如你的缓存服务宕机了/大量缓存过期,会有大量的请求进来直接打到DB上面。结果就是DB 称不住,挂掉。
解决办法:
- 使用集群,保障高可用性 (事前)
- Mysql限流+本地缓存,避免主要业务挂掉(事中)
- 开启Redsi持久化机制,尽快恢复缓存(事后)
- 对于大量缓存同时间过期,给过期时间加上随机值
缓存穿透
请求去查询一条压根儿数据库中根本就不存在的数据,也就是缓存和数据库都查询不到这条数据,但是请求每次都会打到数据库上面去,这种查询不存在数据的现象我们称为缓存穿透。
解决办法:
- 缓存空值
- Bool 过滤
缓存击穿
在平常高并发的系统中,大量的请求同时查询一个 key 时,此时这个key正好失效了,就会导致大量的请求都打到数据库上面去。这种现象我们称为缓存击穿。
解决办法:
已知多个线程查询同一条数据,可以加上互斥锁,第一个线程从数据库查询,其他线程等待。第一个线程查询到数据后加入缓存,之后线程直接查缓存就OK。
缓存与数据库双写一致
可以先删除缓存,然后更新数据库。——延时双删
也可以先更新数据库,然后删除缓存。——消息队列
缓存和数据库会存在短期内的不一致,所以最简单的办法是设置缓存的过期时间(虽然存在短时间的脏数据,旧数据)
复杂一些的解决办法是设置消息队列,
热Key问题
线上redis集群,如果一个key非常火(比如明星效应)导致所有访问都冲往一个redis节点,redis直接崩溃。
咋解决:分两步:
1.首先发现热key,发现热key的方法有许多:
事先估计,通过人为估计热key
- 客户端对key进行流量统计,流量超过阈值的视为热key
- 在代理层流量统计
- 无代码侵入式的,其他系统监听数据包/爬取其他top榜单等
2.通知系统进行处理
- 客户端本地缓存(如开一个Map,或者ehcache)
- Redis 集群数据备份,开几个相同的Redis来顶。
Redis 一致性hash算法
将hash值映射到一个2^32大小的圆环上,每次查询顺时针方向上距离最近的服务器。
如果新增/删除服务器,只会影响邻近的服务器,rehash影响有限。
问题:数据倾斜不均衡
解决:增加大量虚拟节点,保证虚拟节点的均衡,之后将虚拟节点映射到真实节点。通过这种方式,新增/删除服务器只需要修改虚拟节点的分配就行。